[비율·확률]
■ 비율
· 비교하는 양 ÷ 기준량
- 어떤 수량(비교하는 양)의 다른 수량(기준량)에 대한 비의 값을 분수 혹은 소수 등으로 나타낸 것입니다.
- 비율은 비교하려는 모든 비율을 더했을 때 100%가 되어야 합니다.
■ 확률
· 해당 사건이 일어날 경우의 수 ÷ 일어날 수 있는 모든 경우의 수
- 하나의 사건이 일어날 수 있는 가능성을 수로 나타낸 것입니다.
- 확률의 결과값은 주로 백분율로 많이 표현됩니다.
[확률의 덧셈·확률]
■ 확률의 덧셈 법칙
· 서로 동시에 일어나지 않는 사건(배반 사건)의 경우에는 두 사건의 확률을 더하여 확률을 구한다는 개념입니다.
→ 사건 A 또는 사건 B가 일어날 확률 = 사건 A가 일어날 확률 + 사건 B가 일어날 확률
<배반 사건 예시>
- 동전이 앞면 또는 뒷면이 나오는 사건
■ 확률의 곱셈 법칙
· 서로 동시에 일어나는 사건(독립사건 또는 종속사건)의 경우에는 두 사건의 확률을 곱하여 확률을 구한다는 개념입니다.
· 독립 사건 : 사건 A와 사건 B가 동시에 일어날 확률입니다.
= 사건 A가 일어날 확률 × 사건 B가 일어날 확률
= 사건 B가 일어날 확률 × 사건 A가 일어날 확률
<독립 사건 예시>
주사위 2개를 던졌을 때 1과 2가 나올 확률
· 종속 사건 : 사건 A와 사건 B가 동시에 일어나고, 사건 A가 사건 B에 영향을 미칠 확률입니다.
= 사건 A가 일어날 확률 × 사건 A가 일어난 뒤 사건 B가 일어날 확률
<종속 사건 예시>
- 주머니 속에 빨간 공 3개와 파란 공 2개로 총 5개의 공이 있고, 빨간 공 1개를 꺼낸 뒤 다시 넣지 않고 파란 공 1개를 더 꺼낼 확률입니다.
<문제 1>
비가 오는 날 우비가 완판 될 확률이 50%이고, 내일 강수 확률이 40%입니다.
내일 우비가 완판 될 확률은 얼마일까요?
→ 40÷100×50÷100 = 0.4×0.5 = 0.2 = 20%
[평균·분산·표준편차]
■ 정규분포 (normal distribution)
- 평균·분산·표준편차는 데이터가 정규분포를 이루고 있을 때 의미가 있는 지표입니다.
- 데이터가 정규분포를 이룬다는 것은 히스토그램의 봉우리가 하나이며 좌우대칭을 이루는 그래프가 되는 상태를 의미합니다.

■ 분산 (variance)
· (평균과의 차이)^2의 합계 ÷ 전체 데이터 개수입니다.
- 데이터의 흩어진 정도를 나타내는 값입니다.
- 그래프에서는 기울기(경사)로 표현합니다.
■ 표준편차 (standard deviation)
- √[(평균과의 차이)^2의 합계 ÷ 전체 데이터 개수]
- 분산에 루트를 씌운 값입니다.
<예시 1>
평균 거래액이 20,000원인 고객 그룹의 평균 거래액을 26,000원으로 6,000원 올리는 것과
평균 거래액이 50,000원인 고객 그룹의 평균 거래액을 60,000원으로 10,000원 올리는 것 중 무엇이 더 어려울까요?
→ 평균·분산·표준편차를 알면 쉽게 답을 구할 수 있습니다.
<표1> 표준편차 : ₩2,000
| -3SD | -2SD | -1SD | 평균 | +1SD | +2SD | +3SD |
| ₩14,000 | ₩16,000 | ₩18,000 | ₩20,000 | ₩22,000 | ₩24,000 | ₩26,000 |
<표2> 표준편차 : ₩5,000
| -3SD | -2SD | -1SD | 평균 | +1SD | +2SD | +3SD |
| ₩35,000 | ₩40,000 | ₩45,000 | ₩50,000 | ₩55,000 | ₩60,000 | ₩65,000 |
→ 평균 그룹이 ₩50,000인 유저 그룹의 평균 거래액을 ₩60,000으로 올리는 것이 1 표준편차 만큼 덜 어렵다는 것을 알 수 있습니다.
[상관분석]
■ 상관분석
· 상관분석이란 두 변수가 선형적인 관계를 가지는지 분석하는 기법으로 상관계수를 가지고 측정합니다.
- 쉽게 설명하면, 서로 다른 데이터의 관계를 수치화한 것을 의미합니다.
- 상관분석은 두 변수가 서로 상관관계가 있음을 나타낼 뿐 인과관계를 나타내지는 않습니다.
- 상관계수에는 단위가 없기 때문에 단위가 다른 변수들 간의 분석도 가능합니다.
■ 상관계수
- 상관분석에는 상관계수가 -1~1 사이의 값을 가집니다.
- 상관계수가 음의 값(-값)을 가질 경우 음의 상관관계를 가진 것으로 한 변수의 값이 작으면 다른 변수의 값이 커집니다.
- 반대로 상관계수가 양의 값(+값)을 가질 경우 양의 상관관계를 가진 것으로 한 변수의 값이 커지면 다른 변수의 값도 커집니다.
■ 상관계수에 따른 상관관계 정도에 대한 해석
| 상관계수 | 상관관계 정도 |
| ± 0.2 미만 | 상관관계가 거의 없음 |
| ± 0.2 ~ 0.4 미만 | 낮은 상관관계가 있음 |
| ± 0.4 ~ 0.7 미만 | 다소 높은 상관관계가 있음 |
| ± 0.7 ~ 0.9 미만 | 높은 상관관계가 있음 |
| ± 0.9 이상 | 아주 높은 상관관계가 있음 |
[가설 설정부터 결과 분석까지]
■ A/B테스트 구조도
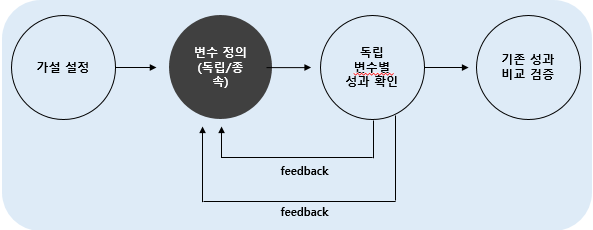
<가설 설정 원칙 1>
· 가설은 검증 가능하게 설정합니다.
- A를 실행하면 B가 증가할 것이다. (X) ← 가정
- A를 실행하면 B가 10% 증가할 것이다. (O) ← 가설
<가설 설정 원칙 2>
· 가설은 데이터 기반으로 설정합니다.
- 가설은 논리적인 유추를 통해 설정해야 하므로 근거(데이터)가 필요합니다.
- 가설 설정을 위한 데이터가 없을 경우, 가설 설정을 위한 데이터 수집 목적의 단기적인 테스트 진행 가능합니다.
- 가설 설정을 위한 데이터가 없을 경우, 다른 레퍼런스와 아이디어를 참고해서 가설 설정 가능합니다.
■ 변수 정의
· 독립 변수 = 원인에 해당하는 변수
- A/B 테스트에서는 테스트를 하고자 하는 영역을 의미합니다.
- A/B 테스트의 A와 B에 해당합니다.
- 독립 변수와 종속 변수는 인과 관계가 이루어지도록 설정합니다.
- 독립 변수의 경우, 빠르고 정확한 테스트 결과 분석을 위하여 한 번에 한가지 영역만 설정합니다.
▷ 독립 변수로 지정할 만한 요소(예시)
- 랜딩 URL 또는 링크 / CTA 버튼 내 문구 / 타이틀 또는 소구 포인트 / 이미지 또는 디자인 / 캠페인 목표 / 비딩(입찰가)
· 종속 변수 = 결과에 해당하는 변수
- A/B 테스트를 통해 개선하려고 하는 영역을 의미합니다.
- 독립 변수와 종속 변수는 인과 관계가 이루어지도록 설정합니다.
- 종속 변수의 경우, 주요 KPI 또는 개선해야 할 지표를 선택하는 것이 좋습니다.
▷ 종속 변수로 지정할 만한 요소(예시)
- 링크 클릭 수 또는 클릭률 / 앱 오픈 수(유입 수) 또는 오픈율 / 회원가입 수 또는 가입률 / 예약 수 또는 예약률
■ 결과 분석
· 독립 변수별 성과 비교
- 독립 변수인 A와 B 중 무엇이 더 종속 변수를 많이 개선 또는 변화시켰는지를 확인하는 과정을 의미합니다.
■ 기존 성과와 비교
- 테스트를 통해 얻은 성과가 기존에 진행하던 미디어/서비스 성과와 비교하였을 때에도 우수한지 검증합니다.
- 기존 성과 대비해서도 우수하다면, 해당 테스트를 전체적으로 적용할 지에 대한 의사 결정을 할 수 있습니다.
'디지털 마케팅' 카테고리의 다른 글
| [데이터 마케팅 첫걸음]콘텐츠 마케팅에 맞는 카피라이팅(1) (0) | 2022.12.21 |
|---|---|
| [데이터 마케팅 첫걸음]마케팅 조사와 디지털 마케팅 (0) | 2022.12.20 |
| [마케터를 위한 기초 수학·통계]기초 수학 개념 (0) | 2022.12.16 |
| [데이터 마케팅 첫걸음]디지털 마케팅 실습을 위한 목표 설정 (0) | 2022.12.15 |
| [데이터 마케팅 첫걸음]디지털 마케팅 미디어 활용 전략 (0) | 2022.12.14 |



